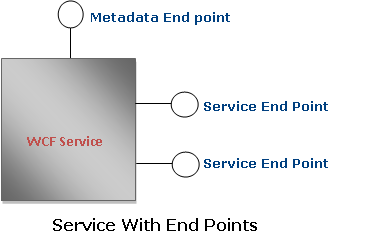
How did it happen?
Once upon a time…
.... Every application was self-contained. A program would consist of a single executable (EXE) file. Complex applications might consist of several executables that were chained to each other. One thing, however, was certain - the executables that accompanied a particular application could be used only by that application. For most programs, you could distribute all of the files used by that program without being concerned that other products might interfere with yours.
In the past few years the size of application files has grown dramatically. The Windows operating environment took advantage of a capability called dynamic linking to allow code modules to be shared by applications. The most important demonstration of the use of this capability is Windows itself - the code modules that contain the functions that make Windows work (the Windows API), are shared by all Windows applications. A code module that can be shared in this way is called a dynamic link library and normally has the extension .DLL.
Initially, this sharing of files was not a problem. Most applications only used the Windows system DLLs, or private DLLs - dynamic link libraries that were rarely shared between applications.
Software Installation of Shared Dynamic Link Libraries
As Windows evolved, Microsoft began to create additional dynamic link libraries that were designed to be shared among its own applications, and still others that were designed to be used by all Windows programmers. These dynamic link libraries contain groups of functions that provide a standard functionality, eliminating the need for each application to implement that functionality independently.
One example of these DLLs is commdlg.dll - the common dialog library. This DLL contains a group of common dialog boxes that can be used by any Windows application to perform standard operations such as obtaining a file name or choosing a color.
Initially, each application that used common dialogs required the distribution of the file commdlg.dll, because it was not included in Windows. Later on, Microsoft included this .dll as part of Windows. A distributed application still needed to include this .dll with distribution because Microsoft continued to include updated versions of the DLL in Windows in order to fix bugs or add new functionality. This was the beginning of DLL Hell.
What happened when a new version of commdlg.dll appeared? Obviously there is no magical way by which it would instantly be replaced for every application that needs it - even if you replaced it in all new builds of a product, all of the previous distribution disks would have the older version of the DLL. It would not be unusual for an individual to own several programs that use this DLL, each of which had a different version of the DLL on its distribution disks.
It is not unusual for users to reinstall software - either during a system upgrade or to change configurations. In many cases users would install software that included an older version of commdlg.dll on a system that already contained a newer version. This would cause the more recently installed version to replace the newer version. As soon the user attempted to run the program that required the newer version, problems would occur ranging from operational difficulties to general protection faults.
The appearance of Version Resources
Microsoft's answer to this problem was to create a mechanism to place a version description into a code module. This was accomplished by embedding a special resource called a Version Resource into the executable file or DLL. A resource is a block of data that can be read from an executable or DLL file by any program. Resources can be read from DLLs on disk, or after they are loaded into memory. A version resource is a resource whose data is in a special format that describes the version of a file and additional information about a file. The version resource makes it possible for installation programs to determine if a later version of a DLL is already present on a system. If so, the installation program can avoid overwriting it with an earlier version.
The Trend Toward Component Based Solutions
Microsoft may have provided a version resource capability, but that alone did not solve all of the problems with distributing applications. Even now, many dynamic link libraries are created without version resources, or their version resources are not updated correctly when the file is modified. Many applications still use installation programs that do not check the version information of existing DLLs, or installation programs that compare the wrong version information.
Still, as long as users had to deal with only a few shared dynamic link libraries, the problem was manageable. This all changed with the appearance of Microsoft's Visual Basic.
Visual Basic is the first product to take full advantage of a new software development philosophy called "Component-Solution" programming. Under this philosophy, programmers take advantage of "off the shelf" software components that implement specific functions. Visual Basic itself is the "glue" that binds these software components.
Under Visual Basic, software components consist of either dynamic link libraries or Visual Basic custom controls (VBXs, OCXs and ActiveXs).
This programming philosophy makes an enormous amount of sense. Why write your own communications function libraries when a single custom control can provide the same capability for a tiny fraction of the price? Visual Basic has literally thousands of different custom controls available, and they are a large part of the reason that it is such a highly effective programming environment. Visual Basic also established a precedent for increased use of reusable software components, which is becoming more popular with other languages as well.
The Distribution Crisis
The component-solution framework for programming has had one serious side effect concerning the distribution of Visual Basic applications. Now instead of a few DLLs that are shared by several applications, there are hundreds of DLLs, VBXs and OCXs that may be shared by literally thousands of applications.
And all it takes is a single DLL, VBX or OCX to be missing, or present in an older version (or even an incompatible newer version), for an application to fail. A poorly designed installation program, user error, registration error or change in the user's PATH environment variable are a few of the ways in which this problem can occur.
Worse yet, there is no reliable way to identify the failure, since the symptoms of the failure can vary from a minor error to a General Protection Fault or memory exception.
But the problems do not end there. Some applications place software components in their own directory, meaning that you can have several versions of the same OCX, VBX or DLL on your system at the same time. The one that is used may depend upon the sequence in which two applications are run, or which component was last registered - leading to a whole list of "intermittent" problems that depend upon the interaction between unrelated applications.
And for those who are using Visual Basic 3.0 or a VBA applications, add the final straw - programs created by these development tools do not have a version resource. This means that there has been no reliable way to prevent the overwriting of newer versions of your own programs.
It is not unheard of for technical support personnel to literally spend hours on the phone trying to track down elusive problems that turn out to be nothing more than the presence of an obsolete software component. With so many problems with so many causes, is it any wonder this headache was called DLL HELL?
How can you escape DLL Hell?
So, how do you go about fixing or preventing this problem (besides taking up some other career)?
If you’re expecting a miracle, I’m sorry to say that there’s no quick fix to this problem yet. The only recommendation I have is to follow Microsoft’s guidelines (what a thought!) for compiling, distributing and installing components.
As a developer, when you are creating a component, be sure to include a version resource and include correct version information - especially with regards to the version number. Do not depend on the version string to identify the version number, be sure all of the version fields are correct.
When you are updating an existing component, be sure that you do not break backwards compatibility. Increment your file’s version number and be sure to update your Type Library version number when adding objects or interfaces to a COM object.
When distributing your applications, be sure to include all files that are not included with the operating system. Try to distribute the newest released versions of the distribution files. If you know that you are not distributing the latest files, be sure to test different combinations of component files that you are distributing with the newer files.
When creating an installation program, be sure to use one that can compare a file’s version resource NUMBER and will replace only files that have an older version NUMBER. Do not use installation programs that compare the file version strings. These strings are not valid for comparison purposes. Install all files that may be used by other applications in the Windows System directory. Register all necessary files.
Avoid Common Mistakes
In the past, it was common for applications to install their main program file and all support files into the same directory. This was safe when all of the support files were only used by the application itself. As the popularity of the component methodology grew and more and more private DLLs are used by different applications, support files were installed to "shared" directories, such as the Windows system directory. Ironically, this trend has now come full circle and some applications are starting to install all files into a private directory again in order to avoid DLL conflict problems.
This method may work in some situations, particularly applications that uses a minimal number of components, and do not use ActiveX components or controls. ActiveX components or controls are required to be "registered" before they can be used. This process results in adding data regarding the file into the Windows registry, including information identifying where the "registered" file is located. Normally, when Windows loads a DLL for your application, it will first search the process’s memory space to see whether the file has already been mapped to this application. Next it would normally search the application’s directory. However, Windows will search for ActiveX components and controls in the registry instead. This altered search order can result in loading the incorrect file for your application. It is also not unusual for another application to install an older ActiveX file into another private directory. When the file is registered in another directory, the file from your private directory will no longer be used by your application.
One consequence of this is that it is not enough for a particular program to have an installation program that works correctly. Another application, or user error can cause a correctly installed application to fail long after the installation. DLL Hell is not an installation problem as much as a problem of ongoing maintanence.
Workable strategies for Dealing with DLL Hell
One solution is, of course, to avoid using components. Unfortunately, now that Windows is based entirely on components, this is not a very effective solution.
Most developers have found that reusable software components have helped more than they have hurt. Components offer enormous program functionality for a fraction of what developing these features in-house would have cost.
As long as there are distributed applications that do not follow Microsoft’s guidelines for ensuring backwards compatibility, embedding and maintaining correct version resource information, comparing numerical version number resource before overwriting older versioned files, installing to shared directories, and registering required files, this DLL Hell problem will exist.
And based on past experience, Microsoft itself will be one of the most frequent sources of these types of problems.
Given that you will have to live with this problem, what can you do about it?
One solution that can be handled on the enterprise level is to impose strict control on the system configuration of each corporate workstation. Or allowing programmers to only install approved applications from a central location.
Note that these approaches do not solve the problem – all they do is allow you the opportunity to test the system configuration before it reaches the end user.
Another approach is to monitor client workstations on an ongoing basis, for example: scanning them every night to make sure that all files are correct according to a reference list and optionally replacing any files that do not match.
These solutions fail in environments where you do not have that type of control, or cases where your customers demand more freedom and less intrusion. In that case you will almost certainly have configuration problems. The best solution to reducing the associated tech support and maintenance costs is to find a way to detect and repair the problems, rather than focus on prevention.
DLL Hell has become a widely recognized problem over the past few years, and you can expect to see more and more companies offering solutions. Desaware has taken the lead in identifying and warning people about this problem. Since 1994, Desaware has pioneered solutions for addressing this problem through its award winning VersionStamper product.
How does VersionStamper help you deal with DLL Hell?
- VersionStamper puts the developer in charge
- Developers can specify files to verify with the aid of VersionStamper's advanced dependency checking software..
- Developers can specify how and when to perform file verification based on the needs of their application or groups of applications.
- Developers can specify how to resolve the problems that are detected.
- VersionStamper supports remote diagnostics
- VersionStamper supports a variety of component conflict notifications.
- VersionStamper supports automatic software updates
Desaware’s VersionStamper was developed from the ground up to detect file conflicts. VersionStamper allows you to specify a list of files and the files attributes to verify. You decide what types of conflicts to look for, how and when to perform the file verification, and how to resolve problems that are detected
VersionStamper includes a number of sample conflict detection code templates that you can use to customize your own solutions. These approaches include displaying a warning to your users, or sending an Email message with detailed configuration information to a central help desk or technical support contact. You can even automatically download and install a correct set of files to your user’s computers. VersionStamper helps you detect the problem right away, and gives you the information you need in order to determine what needs to be fixed.
For more information on VersionStamper, please refer to our web site at www.desaware.com. A demo program is available to download.
Future Windows Technology
NT 5.0 (now renamed NT 2000) will introduce a new technology call Active Install. This new technology is intended to help solve some of the existing DLL Hell problems (while almost certainly creating new problems) for applications that support the Active Install APIs. Deploying Active Install will require modifications to your applications to take advantage of the new capabilities, and the information covered in this white paper should prove helpful when it comes time for you to adopt the new approach. The new Active Install technology will be the subject of a future article on Desaware’s web site. Unfortunately, given the fact that Active Install only works with NT 2000, and considering the time it takes to widely deploy new technologies, it will be years before it will provide an even partial solution for most enterprises.
Conclusion
DLL-Hell is a real problem – one of the most serious problems facing application developers and system administrators today. Hopefully this article has provided you with some insight into how this problem came to exist and how you can manage the problem through the use of sound software deployment strategies. We also invite you to take a look at our VersionStamper system, which can be a helpful tool for reducing support costs related to this problem.